©2021 Reporters Post24. All Rights Reserved.

Cloudflare says a massive outage that affected more than a dozen of its data centers and hundreds of major online platforms and services today was caused by a change that should have increased network resilience.
“Today, June 21, 2022, Cloudflare suffered an outage that affected traffic in 19 of our data centers,” Cloudflare said after investigating the incident.
“Unfortunately, these 19 locations handle a significant proportion of our global traffic. This outage was caused by a change that was part of a long-running project to increase resilience in our busiest locations.”
According to user reports, the full list of affected websites and services includes, but it’s not limited to, Amazon, Twitch, Amazon Web Services, Steam, Coinbase, Telegram, Discord, DoorDash, Gitlab, and more.
Outage affected Cloudflare’s busiest locations
The company began investigating this incident at approximately 06:34 AM UTC after reports of connectivity to Cloudflare’s network being disrupted began coming in from customers and users worldwide.
“Customers attempting to reach Cloudflare sites in impacted regions will observe 500 errors. The incident impacts all data plane services in our network,” Cloudflare said.
While there are no details regarding what caused the outage in the incident report published on Cloudflare’s system status website, the company shared more info on the June 21 outage on the official blog.
“This outage was caused by a change that was part of a long-running project to increase resilience in our busiest locations,” the Cloudflare team added.
“A change to the network configuration in those locations caused an outage which started at 06:27 UTC. At 06:58 UTC the first data center was brought back online and by 07:42 UTC all data centers were online and working correctly.
“Depending on your location in the world you may have been unable to access websites and services that rely on Cloudflare. In other locations, Cloudflare continued to operate normally.”
Although the affected locations represent only 4% of Cloudflare’s entire network, their outage impacted roughly 50% of all HTTP requests handled by Cloudflare globally.
The change that led to today’s outage was part of a larger project that would convert data centers in Cloudlfare’s busiest locations to more resilient and flexible architecture, known internally as Multi-Colo PoP (MCP).
The list of affected data centers in today’s incident includes Amsterdam, Atlanta, Ashburn, Chicago, Frankfurt, London, Los Angeles, Madrid, Manchester, Miami, Milan, Mumbai, Newark, Osaka, São Paulo, San Jose, Singapore, Sydney, and Tokyo.
Outage timeline:
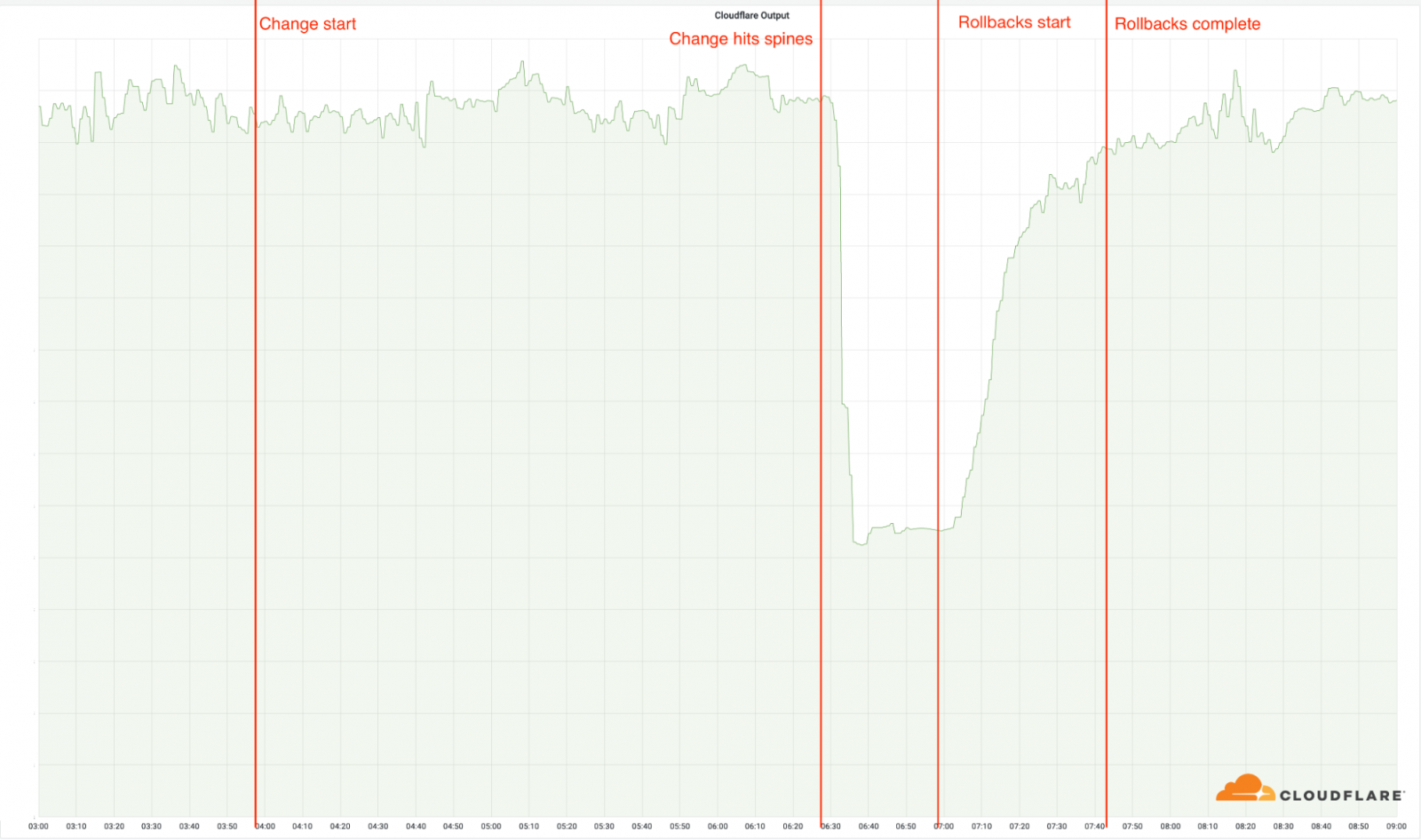
3:56 UTC: We deploy the change to our first location. None of our locations are impacted by the change, as these are using our older architecture.
06:17: The change is deployed to our busiest locations, but not the locations with the MCP architecture.
06:27: The rollout reached the MCP-enabled locations, and the change is deployed to our spines. This is when the incident started, as this swiftly took these 19 locations offline.
06:32: Internal Cloudflare incident declared.
06:51: First change made on a router to verify the root cause.
06:58: Root cause found and understood. Work begins to revert the problematic change.
07:42: The last of the reverts has been completed. This was delayed as network engineers walked over each other’s changes, reverting the previous reverts, causing the problem to re-appear sporadically.